“统计大讲堂”第213讲回顾:偏最小二乘结构方程模型方法、性质及应用
2023-04-28
2023年4月13日上午10:00,由中国人民大学统计学院和教育部人文社科重点研究基地应用统计研究中心共同举办的“统计大讲堂”系列讲座第213讲在明德主楼1016会议室举行。
本次讲座邀请圣母大学心理系教授袁克海作了题为“Partial-least-squares structural equation modeling, its properties and applications”的报告。讲座由中国人民大学统计学院教授吴翌琳主持,采用线上线下相结合的方式,吸引了校内外师生近百人参加。

首先,袁克海以评估数学成绩的方法为例,引出PLS-SEM模型的概念和应用特征。他指出,虽然数据测量误差无法避免,但可以对测量误差进行建模,通过结构方程模型(SEM)等方法评估初始理论与拟合模型之间的关系。接着,袁克海介绍PLS-SEM模型中结构方程(SEM)与路径分析结合的具体方法,即首先为每个个体生成加权得分,再使用加权得分进行路径分析。PLS-SEM易于计算的特点使得它在处理大数据和预测方面有很大的应用潜力,使用这种方法,研究者可以最大限度地提高变量间关系的统计检验力及预测精度。

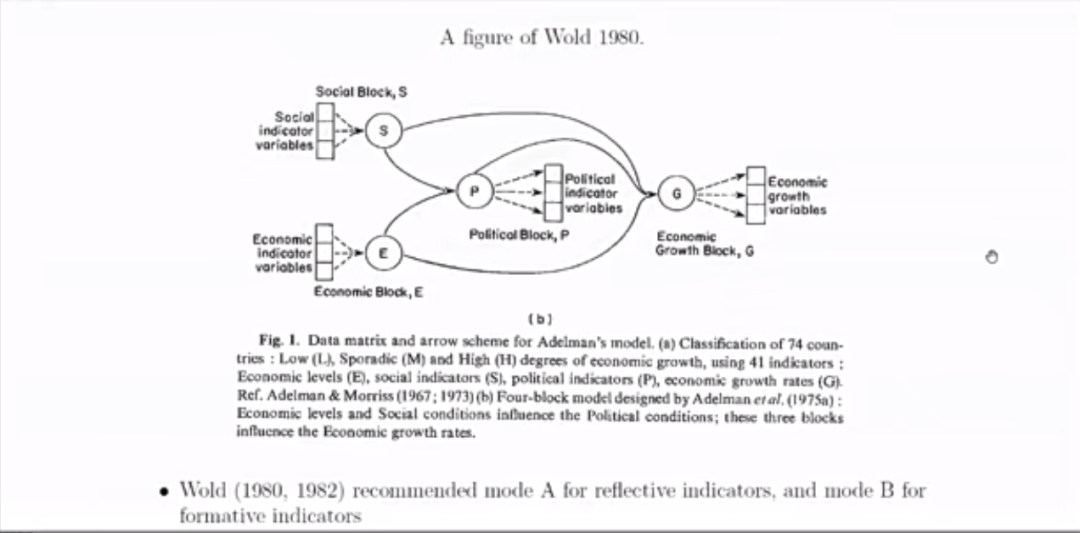
接着,袁克海介绍了两种常用的结构模型,阐述了PLS-SEM模型的部分性质。通过比较模式A和B 的应用路径和特征,他指出两种模式下的权重都可以通过回归分析计算,其中模式B下的权重使得加权得分理论上信度最大。文献中建议采用模式A用于反映性指标测量模型的构建,模式B用于形成性指标模型的构建。袁克海等人的结果表明模式B及一种新的模式BA对反映性指标测量模型更优,并分别进行了详细的解释和论证。他总结道,在PLS-SEM模型下,模式A比模式B在数值上表现更稳定,但相应的加权综合得分的信度可能较低;模式B得到的加权综合得分的信度理论上达到最大,但实际中权重可能为负。模式BA具有模式A和B的优点,是一种非常理想的方法。
最后,袁克海对本次讲座内容进行了总结。他强调,PLS-SEM模型易于计算,通过最优的加权得分使其成为预测和分类个体的首选方法,特别适用于样本量小且结构模型复杂的实例。同时,他指出该模型目前还处在研究过程中,其优化过程受随机误差的影响还需进一步研究。

在提问交流环节,师生就所讲内容积极提出问题,袁克海认真细致地解答了大家的疑问,并就PLS-SEM模型应用的优缺点作了进一步的阐述。