“统计大讲堂”第171讲回顾:因果启发的稳定学习
2021-11-01
10月26日上午,“统计大讲堂”系列讲座第171讲举行。本次讲座采取在线会议的方式,邀请清华大学长聘副教授崔鹏作题为“因果启发的稳定学习”的报告,讲座由中国人民大学统计学院讲师刘越主持。

刘越首先介绍了主讲人的相关信息。崔鹏是清华大学计算机系长聘副教授,博士生导师。研究兴趣聚焦于大数据驱动的因果推理和稳定预测、大规模网络表征学习等。他的论文先后5次获得顶级国际会议或期刊论文奖,并两次入选数据挖掘领域顶级国际会议KDD最佳论文专刊。担任IEEE TKDE、ACM TOMM、ACM TIST、IEEE TBD等国际顶级期刊编委。曾获得国家自然科学二等奖、教育部自然科学一等奖、电子学会自然科学一等奖、北京市科技进步一等奖、中国计算机学会青年科学家奖、国际计算机协会(ACM)杰出科学家等奖项。
崔鹏首先指出了目前人工智能学习结果的稳定性不足的问题。大部分人工智能在进行训练时采用的是笼统的关联统计,而实际上,关联方式可以细分为因果关系,伪关系和样本选择性偏差三类,其中仅因果关系是既稳定又可解释的。
在介绍因果关系的干涉主义定义后,崔鹏提出了用稳定学习来剔除非因果关系的思路:对已有训练数据进行样本重加权,使得加权之后在两组数据之中输出变量仅受单一变量的影响,从而研究二者之间是否为因果关系。

为确定该思想的可行性,崔鹏和团队在2018年证明了在样本空间足够大时,存在一组权重使得各个变量对于输出变量的影响相互独立。对于实际应用中样本空间有限的情况,进行近似处理的方法已经在线性独立框架下取得了较好的稳定性。而在非线性独立框架下,可以通过随机傅里叶特征对于原始数据进行增广。当数据增广到足够高维时,仅需在RFF中保证各维变量的线性独立即可保证原始数据的非线性独立。基于此思路,崔鹏和团队提出了stable-net框架并得到了较好的效果,并在讲座中进行了可视化的效果对比展示,体现了稳定学习的强泛化能力和强解释性。
在思考传统思路为何不能解决OOD标准化问题时,崔鹏对于框架目标进行修正,提出稳定性更强HRM优化框架,在解释原理的同时通过对比展示出了HRM相对于ERM的更优效果。
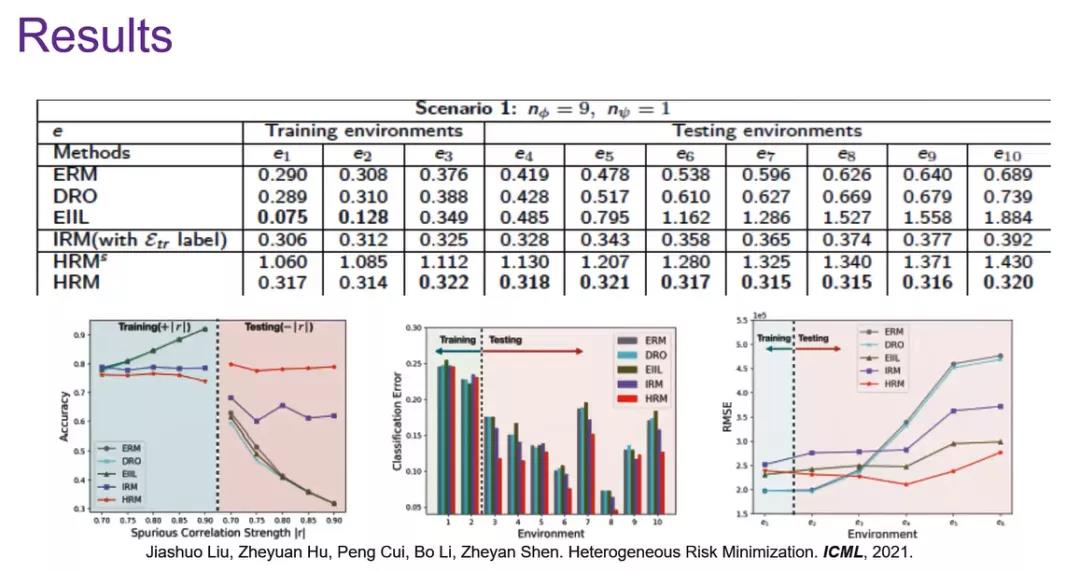
讲座末尾,崔鹏进行了总结。稳定学习可以从因果分析和机器学习两个层面进行进一步的发展。而对于传统的HRM框架我们也应该进行反思,思考其在实践过程中是否应该被一些其他更加实用的模型如ERM等进行替代。
最后,在提问交流环节,在线师生积极参与讨论,崔鹏耐心解答了同学们的疑问,并就荟萃统计和稳定学习的联系等进行了更加深入的讨论。
此后“统计大讲堂”系列将陆续推出更多精彩讲座,敬请关注。